
Tutoriel : recherche dynamique avec htmx, hyperscript et ProcessWire

Créer une recherche dynamique avec très peu de code dans ProcessWire est aisé. Cette recherche ne peut évidemment rivaliser avec les moteurs tels Elasticsearch, Solr, et autres. Elle convient toutefois à la plupart des sites dits « vitrine ». Voici comment nous y sommes parvenus sur le site de Spiria en utilisant la petite librairie htmx et sa consœur hyperscript.
L’objectif
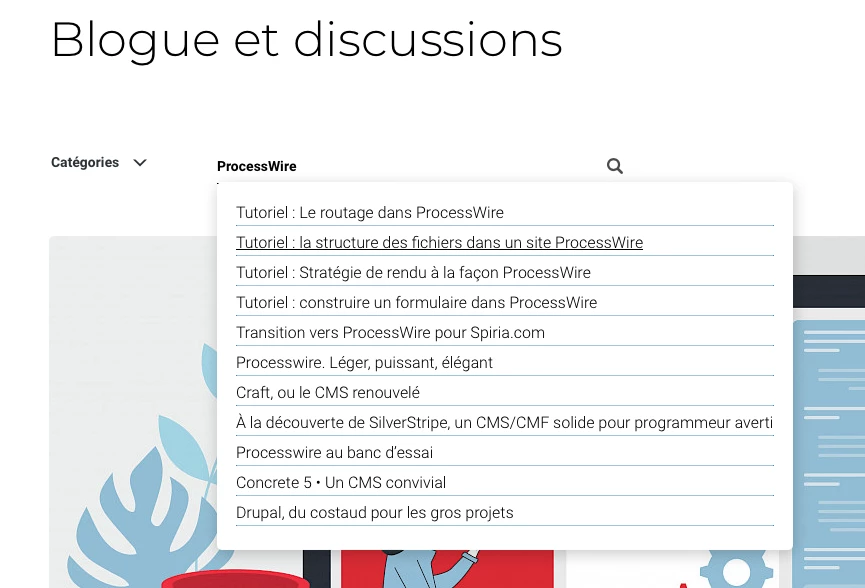
On peut essayer la recherche juste au-dessus de ce texte.
La recette
- Inclusion des librairies htmx et hyperscript (cette dernière est optionnelle).
- Un champ de type textarea intégré aux modèles de pages que l’on veut indexer.
- Un code d’indexation du contenu existant dans le fichier
ready.php. - Un contrôleur de recherche que nous nommons ici
api.php. Ce contrôleur sera également une page possédant le modèleapi. - Un formulaire placé dans les pages nécessitant la recherche.
L’indexation du contenu
Avant de pouvoir programmer, il nous faut indexer le contenu sur lequel on veut appliquer notre recherche. Dans ma preuve de concept, j’ai élaboré deux stratégies. Cela est sans doute surfait, car je ne suis pas certain du gain en rapidité.
- Indexer pour une recherche à un terme.
- Indexer pour une recherche à plusieurs termes.
Pour ce faire, il nous faut introduire deux champs dans chaque modèle où l’on désire une indexation.
- Le champ
search_textqui ne contiendra qu’une occurrence de chaque mot d’une page. - Le champ
search_text_longqui préservera toutes les phrases sans les balises HTML.
On place un hook dans la page ready.php de cette manière:
<?php namespace ProcessWire;
pages()->addHookAfter("saveReady", function (HookEvent $event) {
$p = $event->arguments[0];
switch ($p->template->name) {
case "blog_article":
$french = languages()->get('fr');
$english = languages()->get('default');
$txt_en = $p->page_content->getLanguageValue($english) . ' ' . $p->blog_summary->getLanguageValue($english);
$txt_fr = $p->page_content->getLanguageValue($french) . ' ' . $p->blog_summary->getLanguageValue($french);
$title_en = $p->title->getLanguageValue($english);
$title_fr = $p->title->getLanguageValue($french);
$resultEn = stripText($txt_en, $title_en);
$resultFr = stripText($txt_fr, $title_fr);
$p->setLanguageValue($english, "search_text", $resultEn[0]);
$p->setLanguageValue($english, "search_text_long", $resultEn[1]);
$p->setLanguageValue($french, "search_text", $resultFr[0]);
$p->setLanguageValue($french, "search_text_long", $resultFr[1]);
break;
}
});
Et :
function stripText($t, $s)
{
$resultText = [];
$t = strip_tags($t);
$t .= " " . $s;
$t = str_replace(["\n", ",", "“", "”", "'", "?", "!", ":", "«", "»", ",", ".", "l’", "d’", " "], "", $t);
//$t = preg_replace('/\?|\[\[.*\]\]|“|”|«|»|\.|!|\ |l’|d’|s’/','',$t);
$arrayText = explode(" ", $t);
foreach ($arrayText as $item) {
if (strlen(trim($item)) > 3 && !in_array($item, $resultText)) {
$resultText[] = $item;
}
}
return [implode(" ", $resultText), $t];
}
Si on possède le module ListerPro, il devient facile de sauvegarder en lot toutes les pages à indexer et toute nouvelle page sera par la suite indexée au fur et à mesure de sa création.
La fonction stripText() a pour objectif de nettoyer comme on veut le texte.
La structure

Ce schéma est classique et demande peu d’explications. La librairie htmx permet une simplicité d’appel Ajax.
Le formulaire

- Le formulaire possède une méthode
getqui renvoie à une page de recherche conventionnelle dans le cas où l’utilisateur presse la toucheentrée. - Un champ caché possédant la clé secrète générée à la volée renforce la sécurité.
- Le troisième champ est l’
inputde la recherche dynamique. Il possède une syntaxehtmx. La première commande,hx-post, indique la méthode d’envoi de la donnée vers l’API. Ici, c’est unpost. - La seconde ligne indique où la réponse de l’API sera envoyée, soit
div#searchResulten dessous du formulaire (point 10). - La commande
hx-triggerdécrit le contexte de l’envoi vers l’API. Ici, lorsque l’utilisateur relâche une touche, avec un délai de 200 ms entre chaque lecture de l’événement. - La commande
hx-indicatorest optionnelle. Elle signale à l’utilisateur que quelque chose se passe. Dans l’exemple, l’image#indexsearch(point 9) est affichée. Ceci est automatiquement pris en charge par htmx. - La commande
_=onprovient de la syntaxehyperscript. Elle ajoute une classe à la division#screenWindow. - Nous avons la possibilité de passer d’autres paramètres à la recherche avec la commande
hx-vals. L’exemple donné est simplifié. On envoie la langue de recherche. - C’est un indicateur optionnel. htmx prend en charge l’apparition.
- La dernière commande est encore une fois de l’
hyperscript. Elle enlève le contenu de la recherche quand on clique en dehors de cette région. - Cela est couplé avec le comportement de la division
#screenWindow. Remarquons la simplicité de la syntaxe.
On comprend à la lecture de cet exemple qu’aucun JavaScript n’est appelé, sauf les librairies htmx et hyperscript. On gagnera à visiter le site web de ces deux librairies pour en comprendre la philosophie et les possibilités.
L’API de recherche
L’API réside dans une page normale de ProcessWire. Bien qu’elle soit publiée, elle est « cachée » des recherches du CMS. Cette page permet de répondre aux demandes et de faire intervenir les bonnes fonctions. On peut rassembler plusieurs requêtes au CMS dans ce type de page.
<?php namespace ProcessWire;
$secretsearch = session()->get('secretToken');
$request = input()->post();
$lang = sanitizer()->text($request["lang"]);
if (isset($request['CSRFTokenBlog'])) {
if (hash_equals($secretsearch, $request['CSRFTokenBlog'])) {
if (!empty($request["search"])) {
echo page()->querySite(sanitizer()->text($request["search"]),$lang);
}
} else {
echo __("A problem occurred. We are sorry of the inconvenience.");
}
}
exit;
Dans le cas qui nous occupe :
- On extrait le jeton secret de la session, jeton créé dans la page du formulaire de recherche.
- On traite par la suite tout ce qui est dans la requête
post. Précisons qu’il s’agit ici d’un exemple simplifié. - On compare le jeton avec celui reçu dans la requête. Si tout va bien, on lance la requête SQL. Notre exemple utilise une fonction d’une classe résidant dans
site/classes/ApiPage.php; elle peut donc être appelée directement parpage(). Toute autre stratégie est valable.
Le code suivant représente le cœur du processus.
<?php namespace ProcessWire;
public function querySite($q, $l)
{
$this->search = "";
$this->lang = $l == 'en' ? 'default' : 'fr';
user()->setLanguage($this->lang);
$whatQuery = explode(" ", $q);
$this->count = count($whatQuery);
if ($this->count > 1) {
$this->search = 'template=blog_article,has_parent!=1099,search_text_long~|*= "' . $q . '",sort=-created';
} elseif (strlen($q) > 1) {
$this->search = 'template=blog_article,has_parent!=1099,search_text*=' . $q . ',sort=-created';
}
if ($this->search !== "") {
$this->result = pages()->find($this->search);
return $this->formatResult();
}
return "";
}
protected function formatResult()
{
$html = '<ul id="found">';
if (count($this->result) > 0) {
foreach ($this->result as $result) {
$html .= '<li><a href="' . $result->url . '">' . $result->title . '</a></li>';
}
} else {
$html .= __('Nothing found');
}
$html .= '</ul></div>';
return $html;
}
La fonction formatResult() est simple à comprendre et c’est ici que nous voyons apparaître la balise ul#found qui, rappelons-le, est supprimée par la ligne hyperscript du formulaire.
="on click from elsewhere remove #found"
Dans le code actuel, il n’est pas nécessaire d’ajouter du CSS pour afficher le résultat. Il est placé dans une balise vide #searchResult, il est donc invisible au début. Dès qu’elle est remplie par le résultat de la recherche, tout devient accessible, le CSS étant ciblé sur la liste ul#found et non sur son parent.
Conclusion
Le but de cet article était d’expérimenter avec htmx et hyperscript. Je n’ai fait que gratter à la surface des librairies en devenir. La recherche telle que décrite est perfectible et montre parfois ses limites. Il y a tellement de stratégies possibles de combinaison qu'il faudrait éventuellement proposer des options avancées de recherche. Cela pourrait faire l'objet d'un autre article.
J’aime bien le haiku placé en fin de page de l’introduction sur htmx :
Lassitude du JavaScript :
en quête d’un hypertexte
déjà sous la main(JavaScript fatigue:
longing for a hypertext
already in hand)
Enfin, il existe déjà un excellent module de recherche pour ProcessWire, SearchEngine, qui peut très bien coexister avec le code décrit ici.