

Le routage est une partie importante de la logique de navigation d’un site web. Les programmeurs habitués à des cadriciels tels Laravel ou Symfony doivent coder manuellement celui-ci. Il en va autrement avec ProcessWire. La dynamique entourant les URLs se bâtit au fur et à mesure de la construction des modèles et des pages. Comme tous les CMS, il prend en charge les différentes étapes liées au CRUD (Create, Read, Update, Delete) et possède des fonctionnalités pour traiter les appels AJAX, assainir les URL, etc.
Rappelons tout d’abord quelques caractéristiques de ProcessWire.
- Chaque page d’un site est un objet appelé tout simplement page et prend sa place au sein d’une arborescence.
- Les pages sont contrôlées par des modèles composés de champs.
- L’arborescence ainsi créée établit la route de chacune des pages.
Le diagramme ci-dessous illustre les différentes possibilités de programmation de la route.

 La racine
La racine
Tout d’abord, l’URL « fixe » est celle inhérente à une page. Ainsi, le page Home est toujours « / » ou « /fr » (pour une deuxième langue, ici le français). Tout ce qui est en noir dans les URLs illustrées est dit fixe. La langue fait partie intégrante de la « racine » et est réglée au niveau de la page 1, l’accueil, dans la section « Paramètres ».
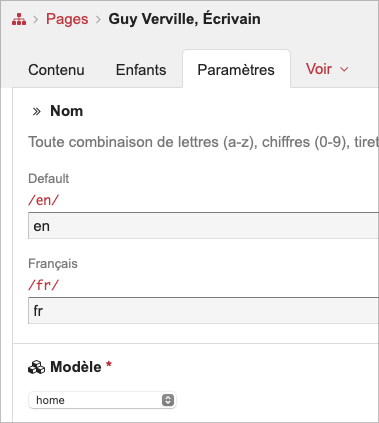
Notons que la page d’accueil sera toujours « / » même si vous indiquez un suffixe comme « en ». C’est la stratégie par défaut d’avoir le nom de domaine initial inscrit comme https://www.site.com au lieu de https://www.site.com/en.
On peut opter pour la seconde option en allant dans Modules/Configuration/LanguageSupportPageNames.
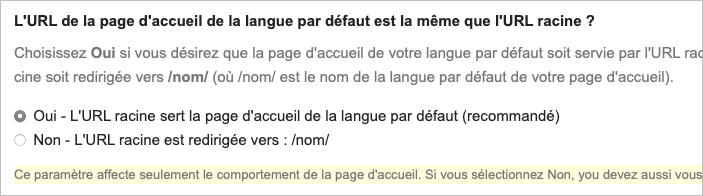
Vous verrez qu’on ne vous recommande pas de choisir cette deuxième option, même si cela est possible. La raison est simple. Si une personne tape https://www.site.com et se voit redirigée vers https://www.site.com/en, les moteurs de recherche comme Google considéreront cela comme deux adresses possédant le même contenu. Google vous suggérera d’enlever cette redirection inutile. La duplication, c’est mal!
La route standard
La route standard est celle qui suit l’arborescence. Le programmeur n’a rien à faire. Comme la page est basée sur un modèle, c’est le fichier PHP du modèle qui est tout de suite pris en charge.
 Les « enfants »
Les « enfants »
Techniquement parlant, tout est enfant de la racine dans ProcessWire, mais si on fait abstraction de celle-ci, le chemin des enfants est montré en vert dans l’illustration. Les enfants suivent la même logique de route standard. Ce sont aussi des routes fixes. ProcessWire se charge de construire celle-ci avec ce que l’on inscrit dans la section Paramètres de la page. Les enfants appartiennent souvent à un autre modèle, donc se comportent différemment du parent.
Notons ici une finesse de ProcessWire en mode multilingue. Supposons l’adresse https://www.site.com/en/blog. Si on tape https://www.site.com/fr/blog, ProcessWire reconnaîtra qu’on veut voir la version française de la même page et changera automatiquement pour https://www.site.com/fr/blogue.
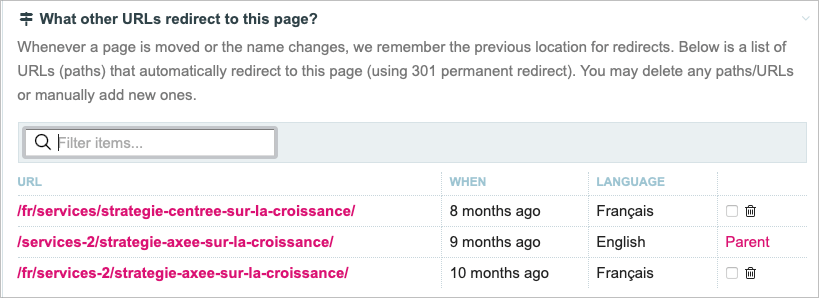
Les redirections automatiques
En activant le module PagePathHistory, intégré à ProcessWire, on peut s’assurer que, si on change le nom de la route dans à l’onglet Paramètres, les redirections se feront automatiquement.
 La pagination
La pagination
Entrons maintenant dans la partie plus dynamique du routage. L’exemple le plus commun est la pagination. On la voit couramment sur des sites possédant trop de pages enfants.
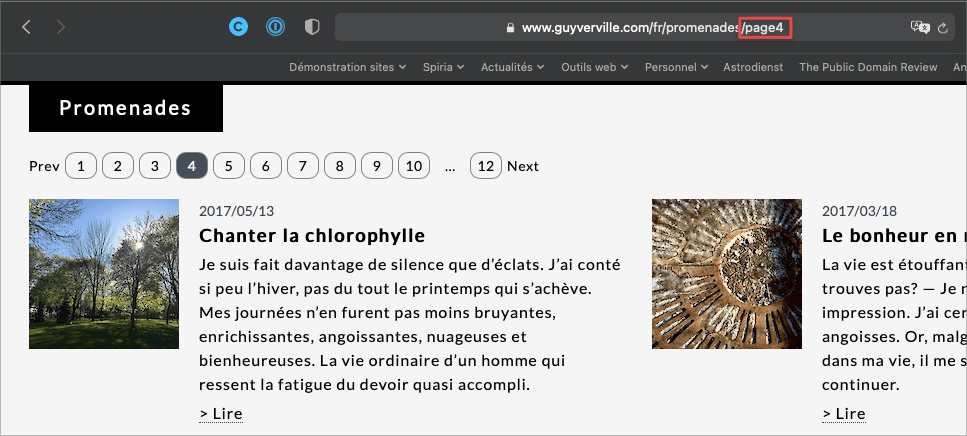
L’activation de la pagination se fait au niveau du modèle, à l’onglet URLs qui regroupe les stratégies discutées ici.
ProcessWire s’occupera de rassembler les pages voulues selon la sélection programmée avec un code similaire à celui-ci :
$articles = pages()->find("template=blog_article,sort=-date_publication, limit=36");
$pagination = page()->renderPagination($articles);
[...]
<div><?=$pagination?></div>
L’objet $input ou input()
ProcessWire traite l’information provenant d’une l’URL en l’attribuant d’abord à l’objet $input. Placez le code suivant dans n’importe quel modèle et tapez une adresse existante sur votre site:
echo '<pre>';
var_dump( input() );
echo '</pre>';
exit;
Vous obtiendrez la structure de l’objet $input qui sera, en principe, vide, sauf peut-être pour une liste de cookies.
object(ProcessWire\WireInput)#314 (6) {
["get"]=>
array(0) {
}
["post"]=>
array(0) {
}
["cookie"]=>
array(7) {
["_ga_S0T7N638Z9"]=>
string(33) "GS1.1.1619658225.3.1.1619659512.0"
["_fbp"]=>
string(29) "fb.0.1616764431218.1660133326"
["_ga"]=>
string(27) "GA1.2.2052500784.1618595859"
["_gid"]=>
string(26) "GA1.2.107615638.1619647242"
["wires"]=>
string(26) "k88d457vhbkbt8kaerrqi5nt2e"
["wires_challenge"]=>
string(32) "bjG/6lhb8sptS732AoFvgARQ7TDhH6ie"
["chosenlanguage"]=>
string(2) "fr"
}
["whitelist"]=>
NULL
["urlSegments"]=>
array(0) {
}
["pageNum"]=>
int(1)
}
Visitons une adresse avec pagination du style présenté dans l’illustration au point 3. Nous obtiendrons le même objet $input, mais la partie pageNum sera renseignée. Aussi simple que cela. ProcessWire s’occupera de trouver les éléments liés à notre programmation.
object(ProcessWire\WireInput)#314 (6) {
["get"]=>
array(0) {
}
["post"]=>
array(0) {
}
["cookie"]=>
NULL
["whitelist"]=>
NULL
["urlSegments"]=>
array(0) {
}
["pageNum"]=>
int(4)
}
 Les requêtes GET et POST
Les requêtes GET et POST
Les requêtes GET ou POST sont aussi placées dans l’objet $input. Elles peuvent provenir d’un formulaire ou d’un appel Ajax. La requête de type GET illustrée au point 4 donnera l’objet suivant:
object(ProcessWire\WireInput)#314 (6) {
["get"]=>
array(2) {
["album"]=>
string(1) "2"
["criteria"]=>
string(4) "blue"
}
["post"]=>
array(0) {
}
["cookie"]=>
NULL
["whitelist"]=>
NULL
["urlSegments"]=>
array(0) {
}
["pageNum"]=>
int(1)
}
À ce stade, c’est au programmeur d’intercepter correctement l’appel URL, ce qui implique d’assainir l’information avec la classe sanitizer() ou autres méthodes PHP. Le processus est le même avec les appels POST. On se référera à mon article sur les formulaires pour un exemple de code.
 Les segments
Les segments
Les segments sont des éléments d’une URL, séparés par une barre oblique « / » et qui ne font pas partie de l’URL de base. On trouve souvent ce genre d’URL dans un contexte d’échange de renseignements, tel le paiement, des appels à une autre partie de site ou à un site externe. La documentation de ProcessWire décrit très bien la méthode.
Sans surprise, on trouvera l’information dans l’objet $input.
object(ProcessWire\WireInput)#315 (6) {
["get"]=>
array(0) {
}
["post"]=>
array(0) {
}
["cookie"]=>
NULL
["whitelist"]=>
NULL
["urlSegments"]=>
array(2) {
[1]=>
string(4) "view"
[2]=>
string(2) "1234567"
}
["pageNum"]=>
int(1)
}
Un exemple de code ressemblerait à celui-ci:
switch (input()->urlSegment(1)) {
case "view":
$url2 = (int)input()->urlSegment(2);
[...]
break;
case "partial":
$url2 = sanitizer()->text(input()->urlSegment(2));
if (isset($url2) && $url2 > 0) {
$status = UPDATING;
[...]
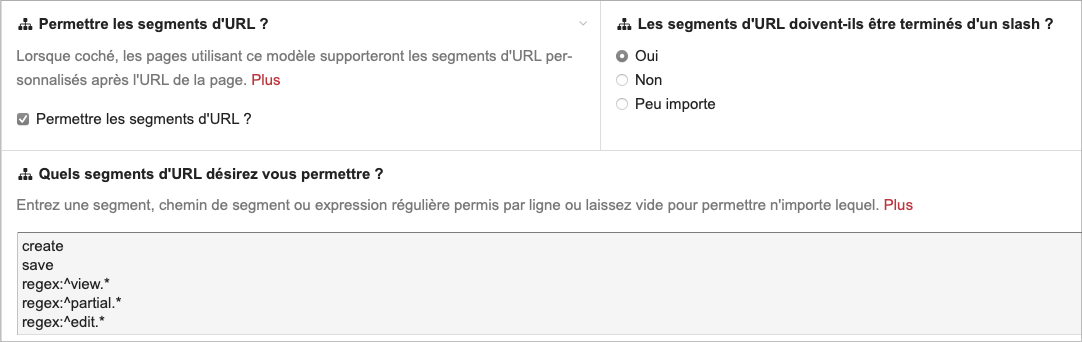
Les segments sont donc passés dans une méthode urlSegment qui décline $input->urlSegments. Pour plus de sécurité, on peut restreindre l’usage des segments dans la même section URLs décrite plus haut avec le bonus de l’utilisation des expressions régulières.
En conclusion
Encore une fois, ProcessWire brille par la puissance et la simplicité de son API. Il est aisé de bâtir un contexte REST avec peu de ligne de codes. Du paiement en ligne, à l’intégration d’un processus Ajax, en passant par la communication entre sites, notre allié est l’objet $input.
Je n’ai fait qu’effleurer les propriétés et méthodes de cet objet, tout comme il y aurait beaucoup à dire sur les autres objets qui collaborent au routage. On gagnera évidemment beaucoup à lire l’API du CMS.