

The first step in our ML process consists in determining what we want to predict. Once this is established, our second step is “data preparation”. Data preparation, together with features engineering, accounts for most of our ML processing time.
Data preparation consists in data collection, wrangling, and finally enfranchisement, if required and when possible.
Data collection
First, gather the data you will need for Machine Learning. Make sure you collect them in consolidated form, so that they are all contained within a single table (Flat Table).
You can do this with whatever tool you are comfortable using, for example:
- Relational database tools (SQL)
- Jupiter notebook
- Excel
- Azure ML
- R Studio
Data wrangling
This involves preparing the data to make them usable by Machine Learning algorithms. (Data Cleansing, Data Decomposition, Data Aggregation, Data Shaping and Transformation, Data Scaling.)
Data Cleansing
Find all the “Null” values, missing values and duplicate data.
Examples of missing values:
- blanks
- NULL
- ?
- N/A, NaN, NA
- 9999999
- Unknown
| #Row | Title | Type | Format | Price | Pages | NumberSales |
|---|---|---|---|---|---|---|
| 1 | Kids learning book | Series – Learning – Kids - | Big | 16 | 100 | 10 |
| 2 | Guts | One Book – Story - Kids | Big | 3 | ||
| 3 | Writing book | Adults – learning- Series | 10 | 120 | 8 | |
| 5 | Dictation | Series - Teenagers | Small | 13 | 85 | 22 |
data_frame below is our Pandas dataset:
#Count the number of missing values in each row in Pandas dataframe
data_frame.isnull().sum()
#Row 0
Title 0
Type 0
Price 1
Format 1
Pages 1
NumberSales 0
If certain rows are missing data in many important columns, we may consider removing these rows, using DELETE query in SQL or pandas.drop() in Python.
Sometimes, the missing value can be replaced by either zero, the main common value, or the average value, depending on the column values and type. You can do this by using UPDATE query in SQL or pandas.fillna() in Python.
In the following code, we have replaced the missing values of “Pages” with the mean:
global_mean = data_frame.mean()
data_frame['Pages'] = data_frame['Pages'].fillna(global_mean['Pages'])
data_frame.isnull().sum()
#Row 0
Title 0
Type 0
Price 1
Format 1
Pages 0
NumberSales 0
And the missing “Format” values with the common value:
#Counts of unique values
data_frame["Format"].value_counts()
Big 2
Small 1
Name: Format, dtype: int64
As “Big” is the most common value in this case, we have replaced all the missing values by “Big”.
# Replace missing "Format" value with the most common value “Big”
data_frame["Format"] = data_frame['Format'].fillna("Big")
data_frame["Format"].value_counts()
Big 3
Small 1
The resulting data_frame is as follows:
| #Row | Title | Type | Format | Price | Pages | NumberSales |
|---|---|---|---|---|---|---|
| 1 | Kids learning book | Series – Learning – Kids - | Big | 16 | 100 | 10 |
| 2 | Guts | One Book – Story - Kids | Big | 13 | 100 | 3 |
| 3 | Writing book | Adults – learning- Series | Big | 10 | 120 | 8 |
| 4 | Dictation | Series - Teenagers | Small | 13 | 85 | 22 |
Make sure you have no duplicates. Delete duplicated rows using DELETE in SQL or pandas.drop() in Python.
Data Decomposition
If some of your text columns contain several items of information, split them up in as many dedicated columns as necessary. If some columns represent categories, convert them into dedicated category columns.
In our example, the “Type” column contains more than one item of information, which can clearly be split into 3 columns, as shown below (Style, Kind and Readers). Then go through the same process as above for any missing values.
| #Row | Title | Style | Kind | Readers | Format | Price | Pages | SalesMonth | SalesYear | NumberSales |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | Kids learning book | Series | Learning | Kids | Big | 16 | 100 | 11 | 2019 | 10 |
| 2 | Guts | One Book | Story | Kids | Big | 13 | 100 | 12 | 2019 | 3 |
| 3 | Writing book | Series | learning | Adults | Big | 10 | 120 | 10 | 2019 | 8 |
| 4 | Writing book | Series | learning | Adults | Big | 10 | 120 | 11 | 2019 | 13 |
| 5 | Dictation | Series | learning | Teenagers | Small | 13 | 85 | 9 | 2019 | 17 |
| 6 | Dictation | Series | learning | Teenagers | Small | 13 | 85 | 10 | 2019 | 22 |
Data Aggregation
This involves grouping data together, as appropriate.
In our example, “Number of sales” is actually an aggregation of data. Initially, the database showed transactional rows, which we aggregated to obtain the number of books sold per month.
Data Shaping and Transformation
This involves converting categorical data to numerical data, since algorithms can only use numerical values.
“Style”, “Kind”, “Readers” and “Format” are clearly categorical data. Below are two ways to transform them into numerical data.
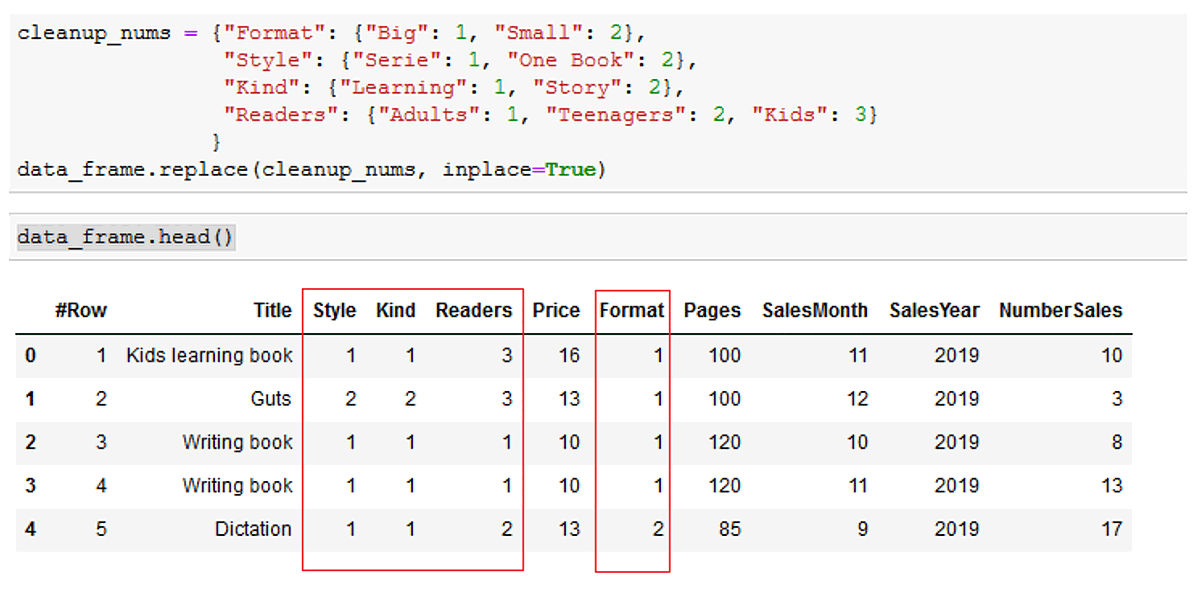
1. Convert all the categorical values to numerical values: Replace all unique values by sequential numbers.
Example of how to do this in Python:
cleanup_nums = {"Format": {"Big": 1, "Small": 2},
"Style": {"Serie": 1, "One Book": 2},
"Kind": {"Learning": 1, "Story": 2},
"Readers": {"Adults": 1, "Teenagers": 2, "Kids": 3}
}
data_frame.replace(cleanup_nums, inplace=True)
data_frame.head()
Result:
| #Row | Title | Style | Kind | Readers | Format | Price | Pages | SalesMonth | SalesYear | NumberSales |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | Kids learning book | 1 | 1 | 3 | 1 | 16 $ | 100 | 11 | 2019 | 10 |
| 2 | Guts | 2 | 2 | 3 | 1 | 13 $ | 100 | 12 | 2019 | 3 |
| 3 | Writing book | 1 | 1 | 1 | 1 | 10 $ | 120 | 10 | 2019 | 8 |
| 3 | Writing book | 1 | 1 | 1 | 1 | 10 $ | 120 | 11 | 2019 | 13 |
| 4 | Dictation | 1 | 1 | 2 | 2 | 13 | 85 | 9 | 2019 | 17 |
| 4 | Dictation | 1 | 1 | 2 | 2 | 13 | 85 | 10 | 2019 | 22 |
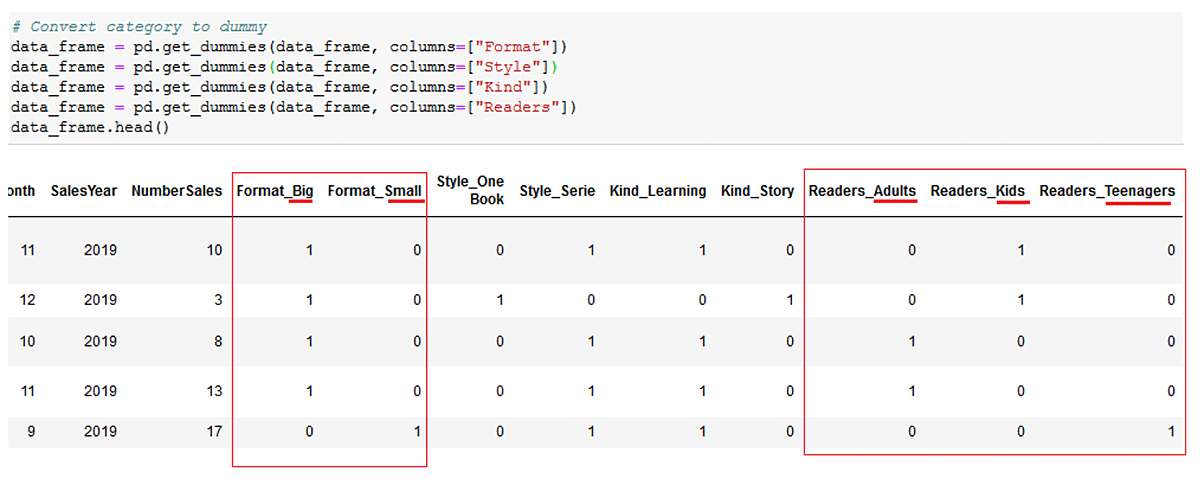
2. Dummies method: This consists in creating a separate column for each single categorical value of a categorical column. As the value of each column is binary (0/1), you can only have one “1” in the newly-generated columns.
How to do this in Python:
# Convert category to dummy
data_frame = pd.get_dummies(data_frame, columns=["Format"])
data_frame = pd.get_dummies(data_frame, columns=["Style"])
data_frame = pd.get_dummies(data_frame, columns=["Kind"])
data_frame = pd.get_dummies(data_frame, columns=["Readers"])
data_frame.head()
You will notice below that “Format” generated 2 columns (“Format_Big” and “Format_Small”), because the “Format” column had 2 single values (“Big” and “Small”). However, “Readers” generated 3 different columns, because it had 3 different values (“Adults”, “Teenagers” and “Kids”).
| Id | Title | Style_Series | Style_OneBook | Kind_Learning | Kind_Story | Readers_Adults | Readers_Teenagers | Readers_Kids | Format_Big | Format_Small | Price | Pages | SalesMonth | SalesYear | NumberSales |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | Kids learning book | 1 | 0 | 1 | 0 | 0 | 0 | 1 | 1 | 0 | 16 | 100 | 11 | 2019 | 10 |
| 2 | Guts | 0 | 1 | 0 | 1 | 0 | 0 | 1 | 1 | 0 | 13 | 100 | 12 | 2019 | 3 |
| 3 | Writing book | 1 | 0 | 1 | 0 | 1 | 0 | 0 | 1 | 0 | 10 | 120 | 10 | 2019 | 8 |
| 3 | Writing book | 1 | 0 | 1 | 0 | 1 | 0 | 0 | 1 | 0 | 10 | 120 | 11 | 2019 | 8 |
| 4 | Dictation | 1 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 13 | 85 | 9 | 2019 | 22 |
| 4 | Dictation | 1 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 13 | 85 | 10 | 2019 | 22 |
*The “Id” and “Title” columns will not be used during our ML process.
The benefit of the dummies method is that all values have the same weight. However, as it adds as many new columns as the number of single categories in each existing column, be cautious of using this method if you already have many columns to consider in the ML process.
On the other hand, if you decide to replace your categorical values by numerical ones, it may give more weight to certain categories whose number is higher. For “Readers”, for example, category 3 will impact the result 3 times, as opposed to category 1. You can imagine what can happen when you have many different values in a categorical column.
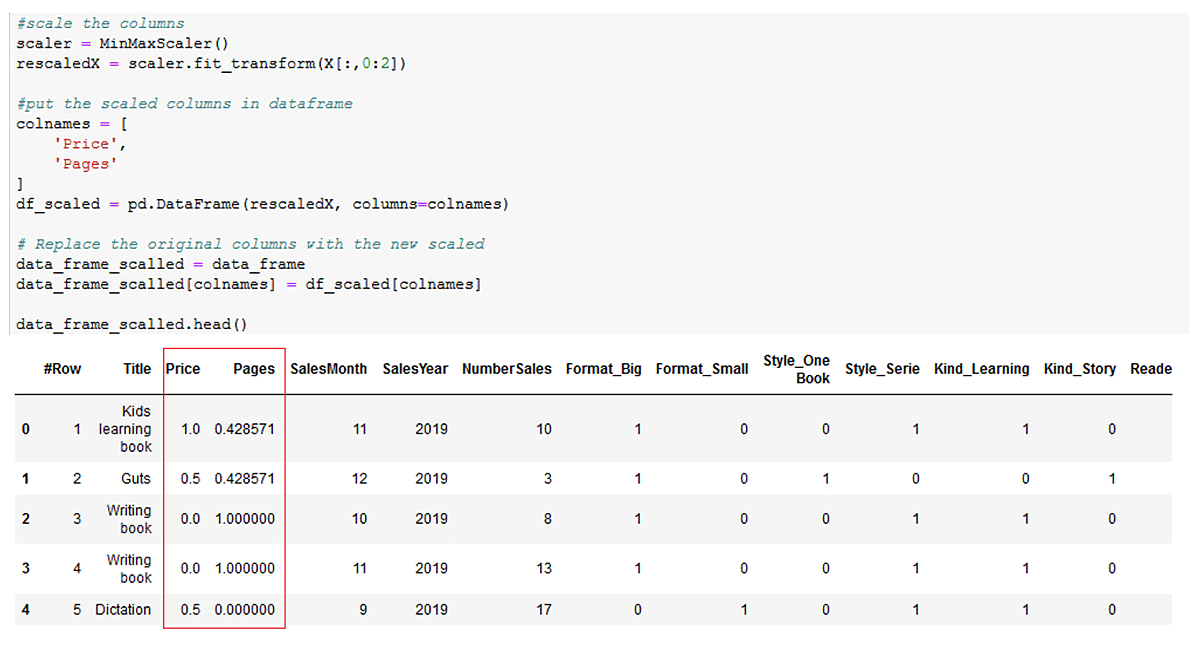
Data Scaling
This process will yield numerical data on one common scale, if it is not already the case. It is required when there is a large variation between features ranges. Data Scaling does not apply to label and categorical columns.
You have to scale again to have the same weight to all features.
In our example, we need to scale the “Price” and “Pages” columns:
- Price [10, 16]
- Pages [85, 120]
These two columns must be scaled, otherwise the “Pages” column will have more weight in the result than the “Price” column.
While there are many methods of scaling, for the purposes of our example, we used the MinMaxScaler from 0 to 1.
#scale the columns
scaler = MinMaxScaler()
rescaledX = scaler.fit_transform(X[:,0:2])
#put the scaled columns in dataframe
colnames = [
'Price',
'Pages'
]
df_scaled = pd.DataFrame(rescaledX, columns=colnames)
# Replace the original columns with the new scaled
data_frame_scalled = data_frame
data_frame_scalled[colnames] = df_scaled[colnames]
data_frame_scalled.head()
The result is the following:
| Id | Title | Style_1 | Style_2 | Kind_1 | Kind_2 | Readers_1 | Readers_2 | Readers_3 | Format_1 | Format_2 | Price | Pages | NumberSales |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | Kids learning book | 1 | 0 | 1 | 0 | 0 | 0 | 1 | 1 | 0 | 1 | 0.42857143 | 10 |
| 2 | Guts | 0 | 1 | 0 | 1 | 0 | 0 | 1 | 1 | 0 | 0.5 | 0.42857143 | 3 |
| 3 | Writing book | 1 | 0 | 1 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 8 |
| 4 | Dictation | 1 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 0.5 | 0 | 22 |
As stated, there are many other scaling methods; how and when to use each one will be the subject of a future article.